High speed search millions of phone numbers
In my last post, I wrote about validating phone numbers in Kenya and in it introduced very specific regular expressions. If you haven’t read it, you might want to do before proceeding with the rest of this post.
A couple of days after the post, I was presented with millions of records having such numbers. The requirement being able to search through these numbers to get the records and get just one of them. As would other persons in my profession, I uploaded the data into a database on my local machine. I chose MS-SQL and used the SQL Server Management Studio (SMSS). Discussion on the choice of tool deserves a post on its own. The original file format was flat (see flat-file format) occupying a little less than 4 GB but when loaded into the database it doubled and there my worries began.
Task 1 Definition
Find details attached to a provided phone number. I’ll use 0722000000 for the purposes of explanation.
Running locally
Immediately after loading the database, I run the query:
SELECT * FROM [dbo].[MyBigTable] WHERE [PhoneNumber] = '0722000000'It took about 17 seconds to get the data. Before the database gurus start complaining, I went ahead and indexed the column
CREATE NONCLUSTERED INDEX IX_MyBigTable_PhoneNumber ON [dbo].[MyBigTable]([PhoneNumber] ASC)This reduced the search to less than 1 second. I was comfortable enough and could proceed to the next task.
Task 2 Definition
Publish an API that can be consumed by other services. I only concentrate on the search section of this task and leave the rest of the fun for your free time :-).
Running on Azure SQL
Going to the cloud I had two MS-SQL options: DBaaS or PaaS. Microsoft Azure has both options here and here. There is a fantastic article comparing the two if you need more acquaintance. I don’t like managing things that I do not have to, so (as you have guessed) I took the DBaaS option, plus I like to optimize things for the least cost possible and that happens to be cheaper for me. From inside SMSS, I exported the database as a data-tier application so as to produce the file (.dacpac) that Azure needed to create a database with existing schema and data. After the database created, the search speeds were an overwhelming average of 15 seconds to get a record even with the correct indices. I was running the database at 100DTUs costing a whopping ~$150 per month. Enter partitioned searches. I split the phone number into two columns to optimize the search query speed. The query looked like this:
SELECT * FROM (SELECT * FROM dbo.Numbers WHERE [PhoneNumber_PK] = '07220') AND WHERE [PhoneNumber_RK] = '00000';The query time hardly changed until I scaled the database to a P2 with 250 DTUs at ~$930 per month ( more details). The query time reduced to 1.72 seconds I only run that for a couple of days to ascertain the problem was not my querying but the database structure. You can correct me in the comments if I am wrong.
Running on Azure Tables
I recalled there are other database options with other different kinds of optimizations. For the uninitiated, there is a lot of material out there on it but you can start here then later see the design guide. Now I will assume you know what a PartitionKey and a RowKey are. From my previous post on validating phone numbers in Kenya, you would have noticed by now that there are a couple of numbers that are common at the beginning. E.g. +254722000000, 254722999999, 0733789012, 0788123456 all have a format we can assume up to the first digit 7 thus considering the unique part to be 22000000, 22999999, 33789012 and 88123456 as the totally unique digits. Specifically, there are 8 unique digits each with a possibility of 10 values, 0–9. Those are 10⁸ total possibilities. Searching will always be slow if the database engine has to scan through all those rows to trying to find one that matches the number you want.
Once again, I split the phone number into two sections but this time not equally. One part becomes the PartitionKey and the other the RowKey. Having too many partitions, in this case, was not necessary, so I used three digits for it. For example, 0788123456 would result in ParitionKey=881 and RowKey=23456. This choice produces a possible 1000 partitions and each partition containing 100,000 rows. Azure storage (which houses the Azure Tables product), replicates your data to a secondary location. From a micro-service perspective:
- the smaller a partition, the faster the replication of data
- the more the partitions, the easier it is to scale
The scaling and replication are handled for us but we have to choose the rest carefully. To query, we do not use a table scan or WHERE clause, instead, we do a direct retrieve. For example, the request is to search the number 0788123456 we would do a retrieve that results in the following HTTP GET request (inferred from the SDK):
https://{accountname}.table.core.windows.net:443/{TableName}(PartitionKey='881',RowKey='23456')The SDK handles generating this for you so all you need to supply is the PartitionKey and RowKey values and the rest is done.
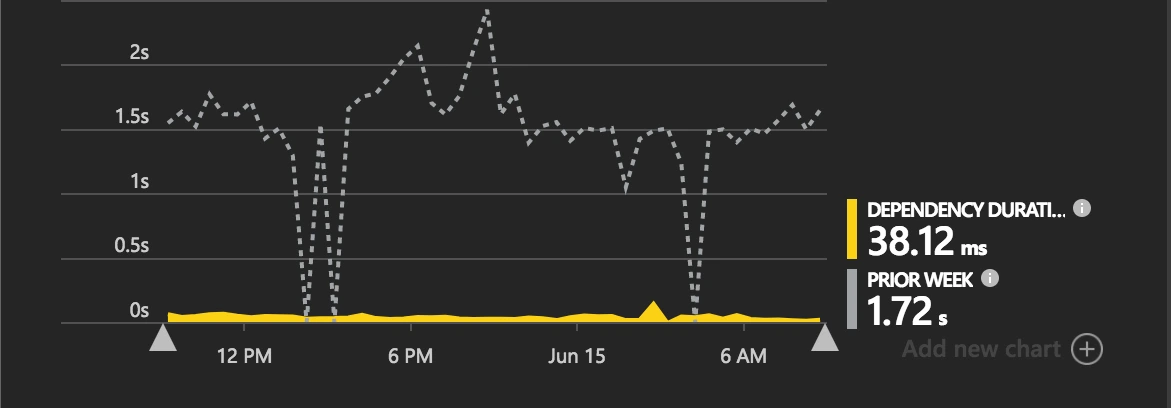
On Azure Tables the query takes less than 40ms as shown on the post image. (97.78% less!). What??????
Query code snippet
For my liking of regular expressions, I used one to extract the PartitionKey and RowKey from the supplied phone number. The expression is: ([0-9]{3})([0-9]{5})$.

To extract the parts in C# 7:
private static readonly Regex KeysRegEx = new Regex(@"([0-9]{3})([0-9]{5})$");
public static (string partitionKey, string rowKey) ExtractKeys(string phoneNumber)
{
if (!string.IsNullOrWhiteSpace(phoneNumber))
{
var match = KeysRegEx.Match(phoneNumber);
if (match.Success)
return (match.Groups[1].Value, atch.Groups[2].Value);
}
return (null, null);
}To query table storage
var keys = ExtractKeys(phoneNumber);
var operation = TableOperation.Retrieve<MyEntity>(keys.partitionKey, keys.rowKey);
var result = await myLookupTable.ExecuteAsync(operation);
var entity = result.Result as MyEntity;Pricing
Azure Tables' pricing on the LRS tier was way less than AzureSQL as at the time of this writing.
- Storage (approximately 10GB) $0.07 * 10 = $0.7 per month
- Query $0.00036 per 10,000 transactions (assuming 100k queries per day or 3.1M per month), $0.00036 * 3.1M/10k = $0.1116 per month
- Total = $0.7 + $0.1116 = $0.8116 per month
CosmosDB (formerly DocumentDB) alternative
I attempted this database offering to see if the results would be useful. I had to run a partitioned collection of 10,000RUs which cost $64.52/month including storage. But the search speeds were terrible. A possible solution to make this work would be to use the PhoneNumber as the document identifier so that you do not do a query but retrieve a document by its id. However, that approach required a lot more engineering with a partitioned collection so I quit.
Conclusion
Azure Tables is not the database for all kinds of work especially not for queries on other columns other than the PartititionKey and the RowKey because the service indexes the two columns and does not allow custom indices yet.
In case you come up with a better way of doing this or already have, please let me know in the comments section below. Till next time, happy coding :-)